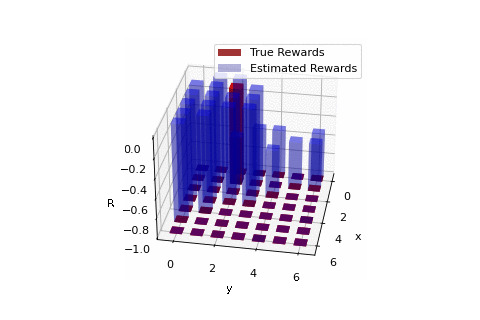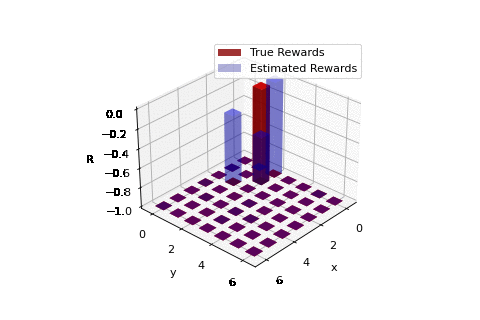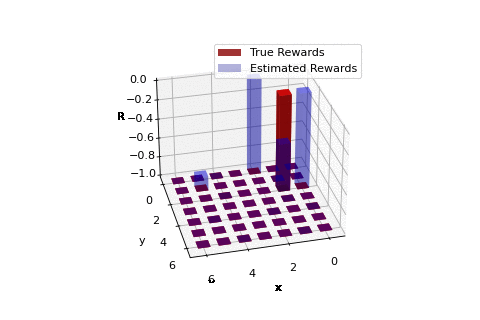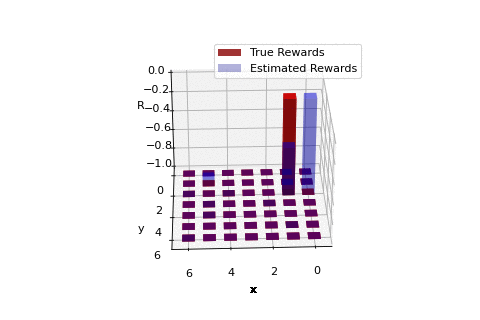
 Rewards learnt using realized trajectories of agent implementing optimal policy.
Rewards learnt using realized trajectories of agent implementing optimal policy.
Inverse Reinforcement Learning over MDPs
Traditional Reinforcement Learning seeks to learn the optimal strategy to complete a mission by performing actions and learning the rewards obtained from them. The rewards function usually define the mission itself, example, the mission of reaching a particular state is captured by setting the reward at all states as -1 and the reward at goal state being zero. The goal in Inverse Reinforcement Learning(IRL) on the other hand is to learn the full reward function that defines the mission, given only the optimal policy. Unsurprisingly, given an optimal policy, the reward function may not be unique. For instance, it is easy to see that the mission of reaching state can be defined by any positive scaling of the reward function we described above and the optimal policy would be the same.
So in our work we discuss a sufficient and necessary condition that the reward function must satisfy. The work primarily follows the work of Ng and Russel, 'Algorithms for inverse reinforcement learning.' Our work provides some additional mathematical insights, primarily through the use of a very simple example. Our work also considers an extention of IRL to solve the problem of apprenticeship learning where we present an example where a robot aims to learn the mission of moving between two points on a grid. The reward function learnt over iterations is highlighted in the GIF to the right. A detailed read can be found here. The codes corresponding the the apprenticeship learning example can be found as a Python Notebook (titled IRL_from_samples.ipynb) here.